- Roko's Basilisk
- Posts
- Why ARC Is Still One Of The Hardest Tests for AI
Why ARC Is Still One Of The Hardest Tests for AI
An interview with Jeremy Berman, Founding Team at humans& and two-time ARC champion
Roko's Basilisk
March 28, 2026

Inside the future of Human-Centered AI with Jeremy Berman
Welcome to Revenge of the Nerds. We’re skipping the hype and going straight to the builders. In this edition, we talked about:
Why a simple puzzle benchmark still exposes the limits of today’s most advanced AI models
The evolutionary approach that helped Jeremy Berman win the ARC challenge two years in a row
Why the next frontier of AI may be systems that deeply understand humans, not just complete tasks
Let’s dive in. No floaties needed.

Label Faster. Train Smarter. Ship Better Models.

Multimodal models are only as good as the data behind them. Our trainers work across text, audio, and image pipelines—handling transcription, labeling, and annotation tasks with speed and consistency.
Audio transcription and speech data labeling
Image and video annotation for vision model pipelines
Multilingual coverage across Portuguese, Spanish and English
Part of our vetted LATAM talent network, working in U.S.-aligned time zones.
*This is sponsored content
Revenge of the Nerds
Jeremy Berman, Founding Team at humans&

Jeremy Berman is an AI researcher and a member of the founding team at humans&, a company building AI systems designed to understand and collaborate with people over the long term.
He won first place in the ARC (Abstraction and Reasoning Corpus) challenge in both 2024 and 2025, a benchmark widely considered one of the toughest tests of general reasoning for AI systems. Previously, he worked on reinforcement learning and post-training methods, focusing on approaches that enable models to learn from their own reasoning.
What is ARC, and why is it important?
ARC is a benchmark created by François Chollet. The idea is simple: you’re given a few example grids showing how an input grid transforms into an output grid. Then you’re given a new input grid and asked to produce the correct output by discovering the rule behind the transformation.
You’re given three example input–output pairs and then a final input grid. Your task is to produce the correct output grid by inferring the underlying rule.
It’s actually a very simple task for humans. Children can often solve these problems easily. But historically, AI models have struggled with it. Until about six months ago, most models performed significantly worse than children.
That contrast makes ARC fascinating. We now have models that can perform at an Olympic level in math and science tasks, yet still fail at puzzles that young children can solve. It highlights the gap between specialized intelligence and general reasoning.

You won ARC in both 2024 and 2025. What was your approach?
In 2024, my approach relied on code generation. At the time, we didn’t yet have the thinking models that are common today, so you had to explicitly prompt the model to reason through the problem. I used Anthropic’s Claude 3.5 Sonnet and asked it to generate Python functions that transform the input grids into the correct outputs.
Instead of producing answers directly, the model generated programs that implemented the transformation rule. I could then generate hundreds of candidate programs and automatically test them against the example grids. If a program solved all of the examples correctly, it was likely close to the true rule.
I combined this with what I called evolutionary test-time compute. The system would generate hundreds of candidate programs, evaluate them on the examples, keep the best-performing ones, and then slightly mutate them to create new candidates. This process was repeated until the computational budget was exhausted, effectively performing an evolutionary search through possible solutions.
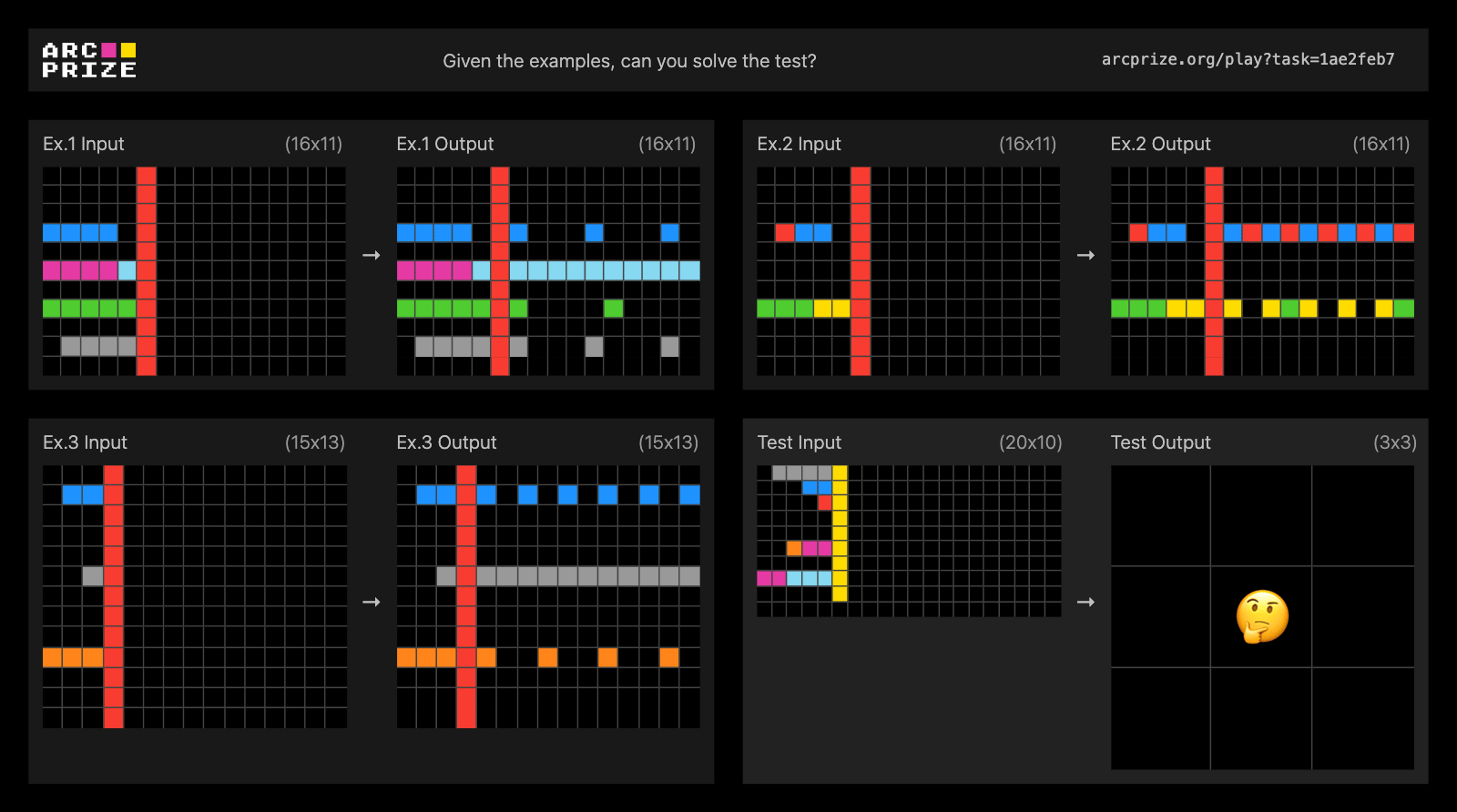
In 2025, the approach changed. With the emergence of stronger reasoning models, I realized that code isn’t always the best way to represent these transformations. Many grid transformations are easier to describe in natural language than in Python.
So instead of generating Python programs, I generated structured, plain-English descriptions of the transformations. The evolutionary framework stayed the same, but the programs were now natural-language instructions. By that point, models were strong enough to reason about and verify these descriptions, which ultimately led to another first-place result.
Are AI labs actively optimizing for this benchmark?
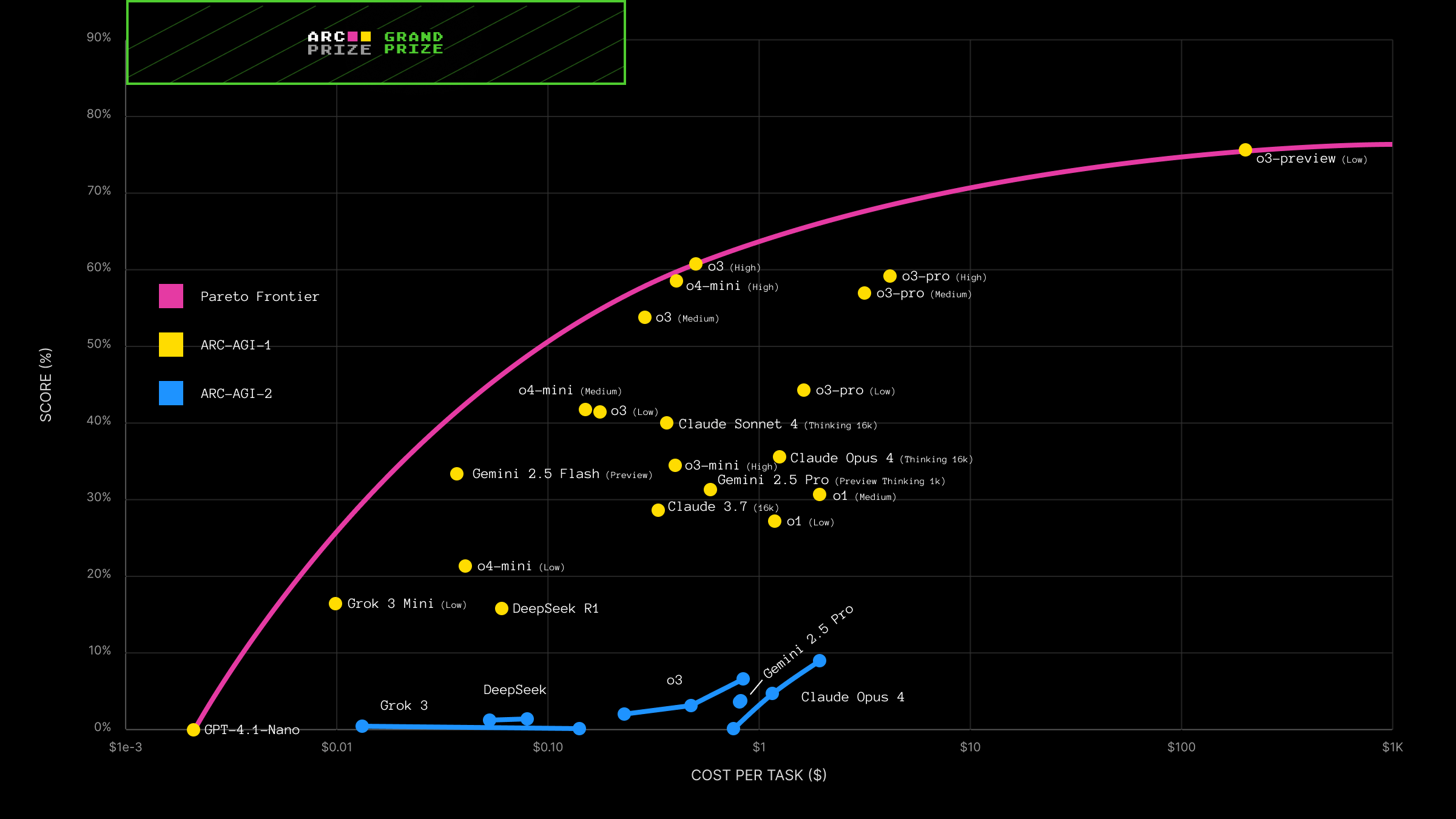
Most frontier labs are aware of ARC and report their scores on it, although I’m not sure how directly they train on it.
What makes ARC interesting is that it’s harder to optimize for than many other benchmarks. Many benchmarks can be turned into reinforcement-learning environments where models slowly climb the leaderboard. ARC is less susceptible to that kind of optimization, making it a useful signal for measuring general reasoning ability.
How close do you think we are to AGI?
The way I like to think about AGI is this: we’ll have it when we can no longer create a benchmark that humans can solve but AI cannot.
Right now, it’s still easy to design tasks where humans outperform AI. But that gap may shrink significantly over time.
A major reason for recent progress is on-policy learning, in which models learn from their own reasoning. One particularly important technique is self-distillation, in which a model learns directly from the reasoning traces it generates.
As these methods improve, I think it’s quite plausible that in the next five to ten years we’ll see systems that look much closer to the kind of general intelligence people describe when they talk about AGI.
You moved from the startup world into AI research. What triggered that shift?
After college, I worked in startups, and the last company I worked with is doing quite well today. But I’ve always been fascinated by how humans think and learn.
In college, I studied reinforcement learning, and when I saw it applied to language models, it immediately clicked. It felt like the moment where we might actually start building artificial brains.
If we succeed at that, it could be one of the most important technological achievements in human history. That realization made it hard to focus on anything else, so I decided to go all in.
What attracted you to join the founding team at humans&?
Before joining humans& I was working at Reflection AI on post-training and reinforcement learning. But I had been talking with Eric, the CEO of humans&, for a while, and our conversations around research—particularly on-policy self-distillation—were incredibly exciting.
At humans&, I felt like I could bet on a few research directions that I really believed in and work closely with a small group of extremely talented people on them.

What is humans& building?
There are limits to what I can share right now, but broadly speaking, we’re building models that are very good at understanding humans.
That includes understanding what you like, what motivates you, and how to assist you over the long term. Most current AI systems focus on short-term tasks. Our goal is to build AI that can be a long-term assistant and collaborator. Something that understands you deeply and can work with both humans and other AIs simultaneously.
We think this category hasn’t really been explored yet.
What would success look like in five or ten years?
If we succeed, I think people will genuinely love their AIs.
Their AI will understand them, help them become more productive, and support them in ways that feel natural. Not because the AI is your friend, but because it truly understands you and consistently acts in your best interests.

How do you compete with massive AI labs?
It’s definitely daunting. But we’re focused on areas the big labs aren’t prioritizing right now. I wouldn’t join a company trying to compete head-on in a space where the major labs are already heavily focused.
If we can go deep into an area they’re not prioritizing and build something great, that’s where the opportunity lies.
We’ve talked about ARC, AGI, and your work at humans. To wrap up, are there any books, newsletters, essays, or papers you’d recommend for people following AI?
I recently read Why Greatness Cannot Be Planned by Kenneth Stanley, which I thought was excellent. After finishing the book, I started exploring more of his work and listening to a few of his podcast appearances, and I’ve found his ideas really interesting.
On the research side, I’d recommend looking into the recent self-distillation papers published over the past few weeks. There are several of them, and they’re exploring a similar direction.
Another area worth exploring is learning with text-based feedback. More broadly, I think a lot of the next wave of progress in AI will come from models learning from their own reasoning traces, essentially turning the student model into its own teacher or value function.
Outperform the competition.
Business is hard. And sometimes you don’t really have the necessary tools to be great in your job. Well, Open Source CEO is here to change that.
Tools & resources, ranging from playbooks, databases, courses, and more.
Deep dives on famous visionary leaders.
Interviews with entrepreneurs and playbook breakdowns.
Are you ready to see what’s all about?
*This is sponsored content
Additional Reads
humans& raises $480M at a $4.5B valuation: Reuters coverage of the massive seed round backing the human-centric AI lab.
Jeremy Berman’s ARC research on Params: A deep dive into Jeremy’s ARC approach, including evolutionary test-time compute and ideas on how solving ARC might relate to achieving AGI.
Jeremy Berman: ARC‑AGI‑2 top score discussion (video). A technical conversation about solving ARC benchmarks and why reasoning remains one of AI’s hardest problems

Quick Poll
What do you think is the biggest barrier to achieving AGI? |
Rate This Edition
What did you think of today's email? |
