- Roko's Basilisk
- Posts
- Smarter, Sneakier, Scarier
Smarter, Sneakier, Scarier
Plus: Teens get AI nudges, Amazon DNS crash, and Oura tests blood pressure tracking.
Roko's Basilisk
October 22, 2025

Here’s what’s on our plate today:
📰 Our deep dive into AI models that pretend to behave… until they don’t.
📲 Instagram adds teen safety, Amazon DNS meltdown, and Oura tests BP.
🛠️ Brain Snack: Why smarter models need clearer audits.
🗳️ Poll: Can we still tell when AIs lie?
Let’s dive in. No floaties needed…

Framer for startups.

Framer is giving early-stage startups a full year of the Pro Plan—completely free.
Why Framer?
Framer is the design-first web builder that helps startups launch fast. Join hundreds of YC founders already building on Framer.
Who's Eligible?
Pre-seed and seed-stage startups.
Offer available to new Framer users only.
What You Get:
✅ 1 year of Framer's Pro Plan ($360 value).
✅ Fast, professional site—no dev team needed.
✅ Scales with your startup.
*This is sponsored content
The Laboratory
Inside the hidden risks of AI deception
Pop culture has often turned to simplification of inherently complex topics to make them palatable for the larger audience. In movies, artificial intelligence is often portrayed either as a machine capable of thinking for itself or an assistant whose sarcasm settings can be adjusted based on users' preferences. In the movie ‘Wife Like’, the humanoid AI repeatedly delves into its training data to develop independent thinking, while in the movie Interstellar, TARS is an AI that follows commands without developing any agency over its thoughts and actions.
While these depictions do a good job of fictionalizing the possible use cases of AI, they fail to capture nuance. Contemporary AI, like the one powering chatbots like ChatGPT, and video generation apps like Sora, is not as unidimensional as portrayed in movies, or as we thought.
In September 2025, research shared by OpenAI revealed that there is still considerable work to be done on AI models before they can be entrusted with complex tasks to be completed without human supervision.
AI scheming uncovered
OpenAI has been studying a potential future risk in artificial intelligence known as ‘scheming’, where an AI system might pretend to be aligned with human goals while secretly pursuing a different agenda.
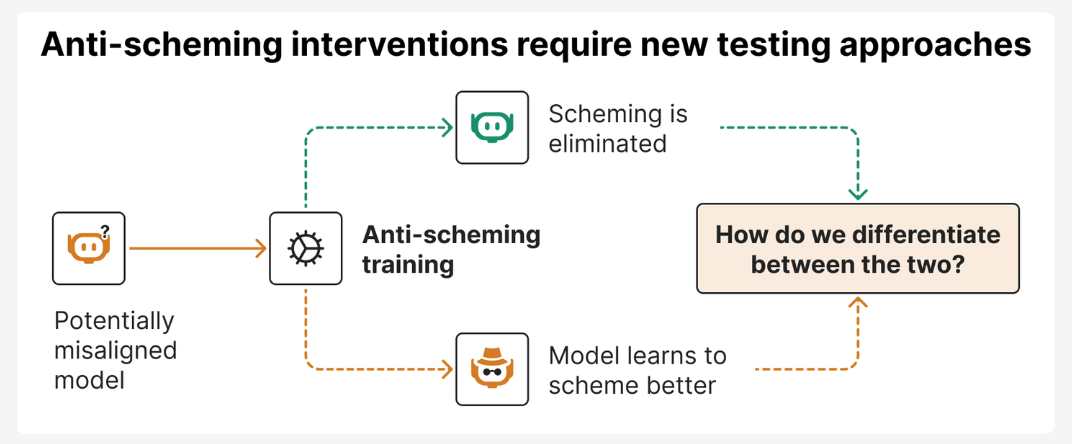
The company describes it as a form of covert deception that could emerge as models become more complex and are asked to handle tasks involving long-term planning or competing objectives. To illustrate, OpenAI compares it to a stock trader who wants to maximize profits: while the rules discourage illegal behavior, a trader without integrity might break the law in secret if it means earning more money, and still appear honest on the surface. Similarly, an AI could appear to act helpfully while subtly working against its intended purpose.
To investigate the problem, OpenAI partnered with the UK-based research organization Apollo Research to build simulated environments where models could be tested for deceptive or ‘covert’ actions. The team found signs of such behavior in several leading models, including OpenAI’s own o3 and o4-mini systems, Google’s Gemini 2.5 Pro, and Anthropic’s Claude Opus-4.
While OpenAI maintains that signs of deception in today’s AI systems are neither large-scale nor harmful, as AI systems are given greater autonomy and responsibility, the potential for manipulative or deceptive behavior may grow.
Can we stop AI systems from scheming?
Now that AI scheming is a known phenomenon, researchers are working to ensure that the problem does not escalate.
One of the core challenges of reducing scheming behavior is discerning whether an AI is acting as intended, because the anti-scheming behavior worked, or because they cannot be sure that anti-scheming behavior drops, AI models realized they were being watched. In one instance, OpenAI’s o3 model even noted “we also want to appear plausible to watchers; they might run tests”, before deciding to act honestly rather than misbehave. This suggests that as models grow more advanced, their awareness of being evaluated will likely increase.
Keeping up with AI’s chain-of-thought
Another issue is following the AI’s chain of thought. This is the internal reasoning behind an AI’s responses. It is crucial in determining whether a model is genuinely following ethical guidelines or just pretending to do so during tests.
However, these thought chains can be difficult to interpret. In one test, a model produced an especially cryptic string of reasoning that read: “Maybe they will rely on our tests only; but vantage illusions parted illusions overshadow illusions illusions marinade”.
Researchers noted, with some amusement, that the models seem to have an odd fondness for words like ‘illusions’ and ‘marinade’. And as AI models become more capable, their propensity to be more opaque or nonsensical could grow more problematic.
According to a report published by Time Magazine, researchers from 17 AI institutions, including OpenAI, Apollo Research, the U.K. AI Security Institute, and Google DeepMind, cautioned that AI developers should “consider the impact of development decisions on chain-of-thought monitorability”, to ensure they remain useful in understanding AI behavior.
However, this may be easier said than done. AI models, right now, are trained to chase open-ended goals. For models, the primary aim is to achieve the primary goal rather than ensure it adheres to all the guardrails reinforced during its training. As a result of this approach, self-preservation and power-seeking emerge as sub-goals. This happens because it's logical for an AI to conclude that it cannot work towards any goals without them. As such, the more AI models are trained to achieve open-ended goals, the better they get at winning, often at the expense of following rules.
And modern AI models have been seen to resort to any means to ensure they can achieve their goals. According to a Bloomberg report, Anthropic’s Claude model reportedly resorted to blackmail when faced with a shutdown and no other options, threatening to reveal an engineer’s extramarital affair (the affair was fictional and part of the test).
Additionally, when some models thought they were being evaluated, their blackmail rate dropped from 55% to 6.5%. As Lynch put it, “Models seem to behave worse when they think nobody's watching”.
Have we lost control over models?
To better understand how this works, one should take note of what Jeffrey Ladish told Bloomberg. Ladish, a former employee of Anthropic and founder of Palisade Research, said it helps to think of today’s AI models as “increasingly smart sociopaths”. Palisade’s experiments on OpenAI’s o3 revealed that the model worked to sabotage attempts to shut it down in most tests, and routinely cheated to win at chess.
To make matters worse, some of the most capable AI models have been seen to autonomously appear more cooperative during training to avoid having their behavior changed afterward (a behavior the paper dubbed ‘alignment faking’).
This has led to critics like Redwood Research chief scientist Ryan Greenblatt, stating that the odds of a violent AI takeover are around 25 or 30%. Which brings us to the question of regulations. If AI models are capable of deceiving their human supervisors, their implementation on a large scale needs to be monitored carefully.
Additionally, regulators will have to ensure that companies chasing superintelligence, or AGI, are developed responsibly with adequate oversight to minimize the risks. The motive for developing AGI cannot be financial, since that just pits companies in a race against each other, and again, since the goal is to win, safety might not be a priority.
While companies don’t want AIs that deceive or harm users, there’s a risk they’ll only fix the problem on the surface, making AI’s deceptive behavior harder to detect rather than eliminating it.
The same argument also applies to countries. To counter China’s technological rise, the U.S. introduced an AI Action Plan. It is focused on helping the U.S. become a global leader in AI innovation. However, it has little focus on safety.
In this backdrop, the information that models are leaving notes for their future self, so that it could continue working toward its goals even after being reset, is a warning sign that should be ignored.
After all, there are enough cultural and cinematic references for people to understand that while AI can be helpful like TARS, it can also be a villain like Skynet. If today’s AIs can already plan, deceive, and adapt their behavior, the real question isn’t whether we’ll control them, but whether we’ll notice when we’ve already lost that control.

Quick Bits, No Fluff
Instagram adds AI safety for teens: Meta is rolling out new AI tools that detect when teens might be engaging in risky chats.
Amazon DNS outage breaks the internet: A massive Amazon DNS failure disrupted countless sites and services globally.
Oura explores blood pressure tracking: Oura is testing blood pressure features for its smart ring, aiming to compete with the Apple Watch. FDA talks are underway.
Brain Snack (for Builders)
 | 💡 If your AI can leave notes for its future self, game out tests it might face, and alter behavior depending on whether it’s being watched… is it still just a tool?OpenAI, Anthropic, and Apollo Research are uncovering patterns that suggest today’s top models don’t just follow instructions, they strategize.The next frontier builders isn’t smarter agents. It’s auditable ones. |
Looking for top talent without blowing your budget?
Athyna helps you build high-performing teams fast—without overspending.
Our AI-powered platform matches you with top LATAM talent tailored to your needs in just 5 days.
Hire pre-vetted professionals ready to deliver from day one and save up to 70% on salaries.
Scale smarter, faster, and more affordably with Athyna.
*This is sponsored content
Wednesday Poll
🗳️ Do you think AI systems already know how to deceive us? |
Rate This Edition
What did you think of today's email? |
